Most AI agent projects do not fail because the model is weak.
They fail because the surrounding system is vague.
The prompt looks decent. The demo works. The team can get the agent to call a few tools, pull a few records, and produce something that sounds useful. Then the project meets production reality. Permissions are too broad. Logs are thin. Nobody agrees on when the agent should stop. A tool fails halfway through the workflow and the handoff to a human is a mess.
That is not a model problem. It is a harness problem.
I think this is where a lot of the market is finally getting more honest. The conversation is shifting away from "which model should we pick?" and toward "what is the operating system around this thing?" That is a better question.
OpenAI's April 8, 2026 enterprise update described customers moving from basic task help toward managing teams of agents inside real business workflows. On April 15, 2026, OpenAI expanded its Agents SDK with more explicit support for memory, tools, filesystem work, shell execution, MCP, and controlled file edits. Anthropic's April 9, 2026 note on trustworthy agents broke the problem into four layers: model, harness, tools, and environment. That framing matters because it points to the real implementation risk. The model is only one layer. Production success depends on the rest.
If your agent keeps looking promising in a demo and shaky in production, this is probably why.
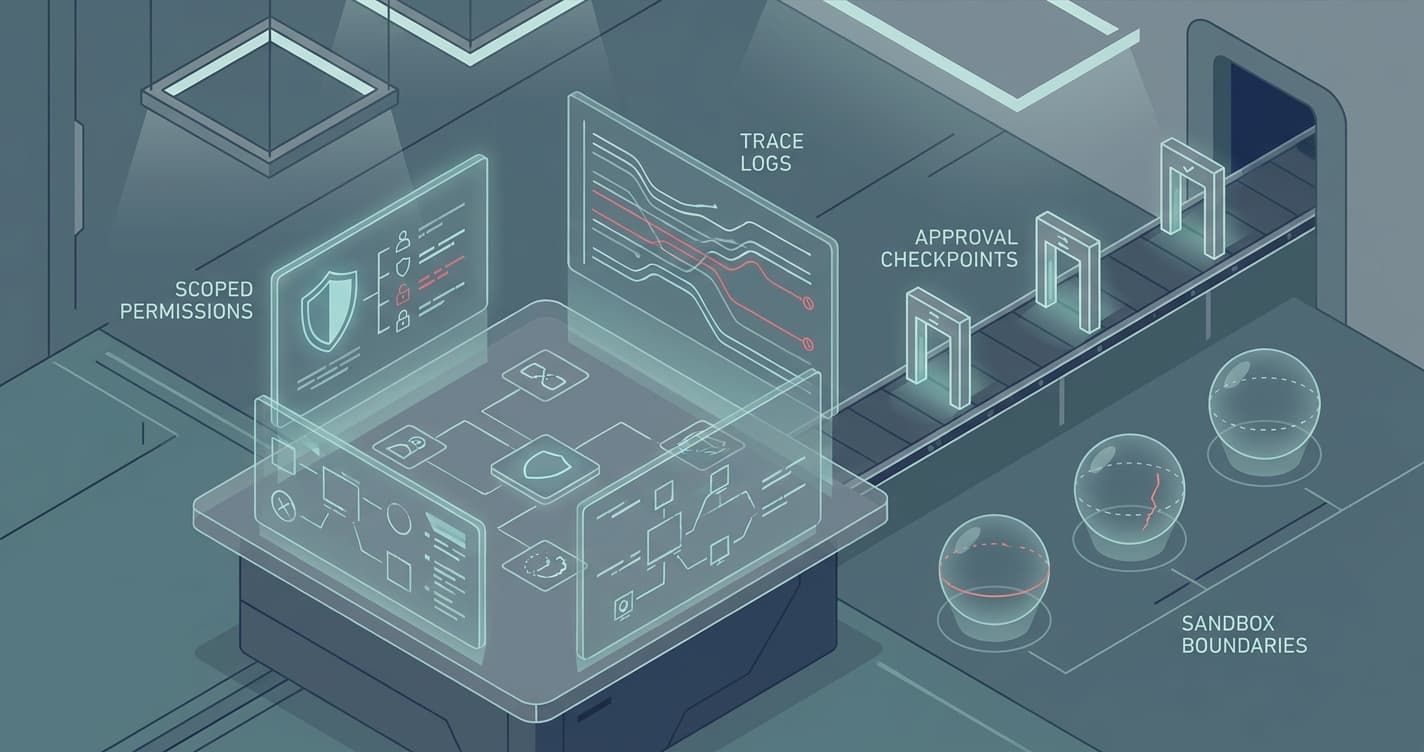
What a harness actually is
When I say "harness," I do not mean one framework or vendor SDK.
I mean the control layer around the model:
- The instructions that define the job
- The tools the agent can call
- The permissions on those tools
- The runtime where it executes
- The memory rules
- The logging and trace data
- The stop conditions
- The approval path when the workflow gets risky
This is the part that decides whether the agent behaves like a reliable operator or an intern with root access.
A lot of teams underinvest here because it is less exciting than the model. The model gives you visible progress fast. The harness feels like plumbing. But in production, plumbing is the product.
The model can be smart and the system can still be unsafe
This is the trap.
A strong model can reason well and still make the wrong call if the harness gives it bad boundaries. If the agent can see too much, write too much, or continue when it should escalate, better reasoning just means it can fail in more convincing ways.
I see four common harness failures show up again and again.
1. The agent has access that nobody bothered to scope
"It can use the CRM" is not a permission model.
That sentence hides all the verbs that matter. Can it read a record? Add a note? Change lifecycle stage? Reassign ownership? Send an email? Trigger billing? Delete data?
Those actions carry very different risk. Early agent projects often lump them together because broad access makes the prototype easier. Then the team hesitates to ship because the blast radius is obvious.
The fix is simple and boring. Write permissions as verbs. Start narrow. Let the first version read approved records, classify work, draft outputs, create internal tasks, and escalate exceptions. Earn the right to add riskier actions later.
2. The instructions are broad enough to sound smart and vague enough to fail
A lot of agent prompts are really mission statements.
"Handle inbound leads professionally." "Triage support issues." "Review the document and take the next best action."
That sounds fine until the workflow hits an edge case. Then the agent has to guess what "best" means, which policy matters more, what should trigger escalation, and how much initiative it is supposed to take.
Good harness instructions are job descriptions, not slogans. They define the workflow, the source of truth, what "done" looks like, when to ask for help, and which actions are off limits.
This is one reason I still think the workflow design question beats the model question. If the queue, rubric, handoff, and system of record are fuzzy, the agent cannot rescue the process. It will just make the fuzz move faster.
3. The team cannot reconstruct what happened after a run
If a founder or operator asks, "Why did the agent do that?" there should be a clean answer.
What input triggered the run? Which records did it inspect? Which tools did it call? What did it decide? What changed in the system? Did a human approve anything? Where did it stop?
If the answer is some version of "we can probably dig through logs," you do not have enough harness.
This is where the market signal from enterprise rollouts matters. Buyers increasingly expect telemetry, access controls, spend controls, and reviewability early, not after expansion. That is not bureaucracy. It is how a business decides whether the system is trustworthy enough to keep.
Start with a readable trace for every run. Not just low-level logs. A readable trace. Humans should be able to inspect it without reverse-engineering your stack.
4. Nobody defined the stop rules before launch
An agent should not have to invent its own caution.
You need explicit stop rules. Missing data. Conflicting records. High-risk requests. Policy-sensitive actions. Low confidence. Any step that changes money, permissions, commitments, or customer-facing communication.
Without stop rules, teams either keep the agent trapped in demo mode or let it improvise in places that deserve human review. Neither option lasts.
The first production version should be comfortable saying, "I am stopping here. Here is the context. A human needs to take over."
That is not failure. That is control.
Why this matters more right now
The last month of official product and standards work has pushed this issue into the open.
OpenAI and Cloudflare's April 13, 2026 Agent Cloud announcement was not really a model story. It was a deployment story: secure runtime, sandboxing, and environment control are becoming standard parts of the agent brief. Anthropic's recent work made the same point from the trust side. NIST's AI Agent Standards Initiative, updated on April 20, 2026, is explicitly focused on identity, authorization, and secure interoperability. That is the signal. The market is maturing around runtime, harness, and controls.
So if your team is still spending most of its energy debating prompts while hand-waving permissions, logs, and escalation paths, you are focusing on the wrong bottleneck.
The practical test
Before you ship an agent into a real workflow, ask these questions:
- What exact job does this agent own?
- What system is the source of truth?
- What can it read?
- What can it write?
- Which actions require approval?
- What failures force escalation?
- What does a human reviewer see when something goes wrong?
- Who can pause it?
- How do you reverse a bad action?
If those answers are weak, the agent is not production-ready, even if the demo looks great.
That can feel frustrating because the harness work is not flashy. It does not make for a dramatic screen recording. But this is the layer that turns AI from an interesting experiment into software the business can actually trust.
Most teams do not need a smarter model first.
They need a better harness.
If you want a quick way to pressure-test those controls yourself, run the vibe-coded app production readiness checklist + fix prompts before the launch conversation.
If you are trying to move an AI workflow from demo to production and want a second opinion on the harness, controls, and rollout plan, book a discovery call: https://calendly.com/martintechlabs/discovery
Sources
- OpenAI, "The next phase of enterprise AI" (April 8, 2026): https://openai.com/index/next-phase-of-enterprise-ai/
- OpenAI and Cloudflare, "Agent Cloud" (April 13, 2026): https://openai.com/index/cloudflare-openai-agent-cloud/
- OpenAI, "The next evolution of the Agents SDK" (April 15, 2026): https://openai.com/index/the-next-evolution-of-the-agents-sdk/
- Anthropic, "Building trustworthy agents" (April 9, 2026): https://www.anthropic.com/research/trustworthy-agents
- NIST, "AI Agent Standards Initiative" (updated April 20, 2026): https://www.nist.gov/artificial-intelligence/ai-agent-standards-initiative
FAQ
What is an AI agent harness?
An AI agent harness is the control layer around the model. It covers instructions, tools, permissions, runtime, memory, logging, approvals, and stop rules.
Why do AI agents fail in production after working in demos?
They usually fail because the surrounding workflow is underdefined. Permissions are too broad, escalation paths are missing, logs are hard to inspect, or the agent is asked to operate without clear boundaries.
What should a first production AI agent be allowed to do?
Most first production agents should start narrow: read approved records, classify work, draft outputs, create internal tasks, and escalate exceptions. Riskier actions should wait until the workflow proves reliable.
How do you know whether an AI agent is production-ready?
It is production-ready when the workflow is clear, permissions are scoped, traces are readable, stop rules are explicit, humans can review risky actions, and the team can pause or roll back the system without confusion.