AI POC vs Production Sprint: When to Stop Proving and Start Shipping
A practical guide to deciding whether your team still needs an AI proof of concept or now needs governed execution with publish authority, scoped access, approval rules, and usable run evidence.
Most teams do not get stuck because the model failed. They get stuck because they proved the model could do the task, then realized they had not proved the workflow could survive real operations. If the conversation is still about whether the task is possible, run a proof of concept. If the conversation has shifted to publish authority, app scope, approval placement, workflow identity, or what evidence survives each run, you are already in production-design territory.
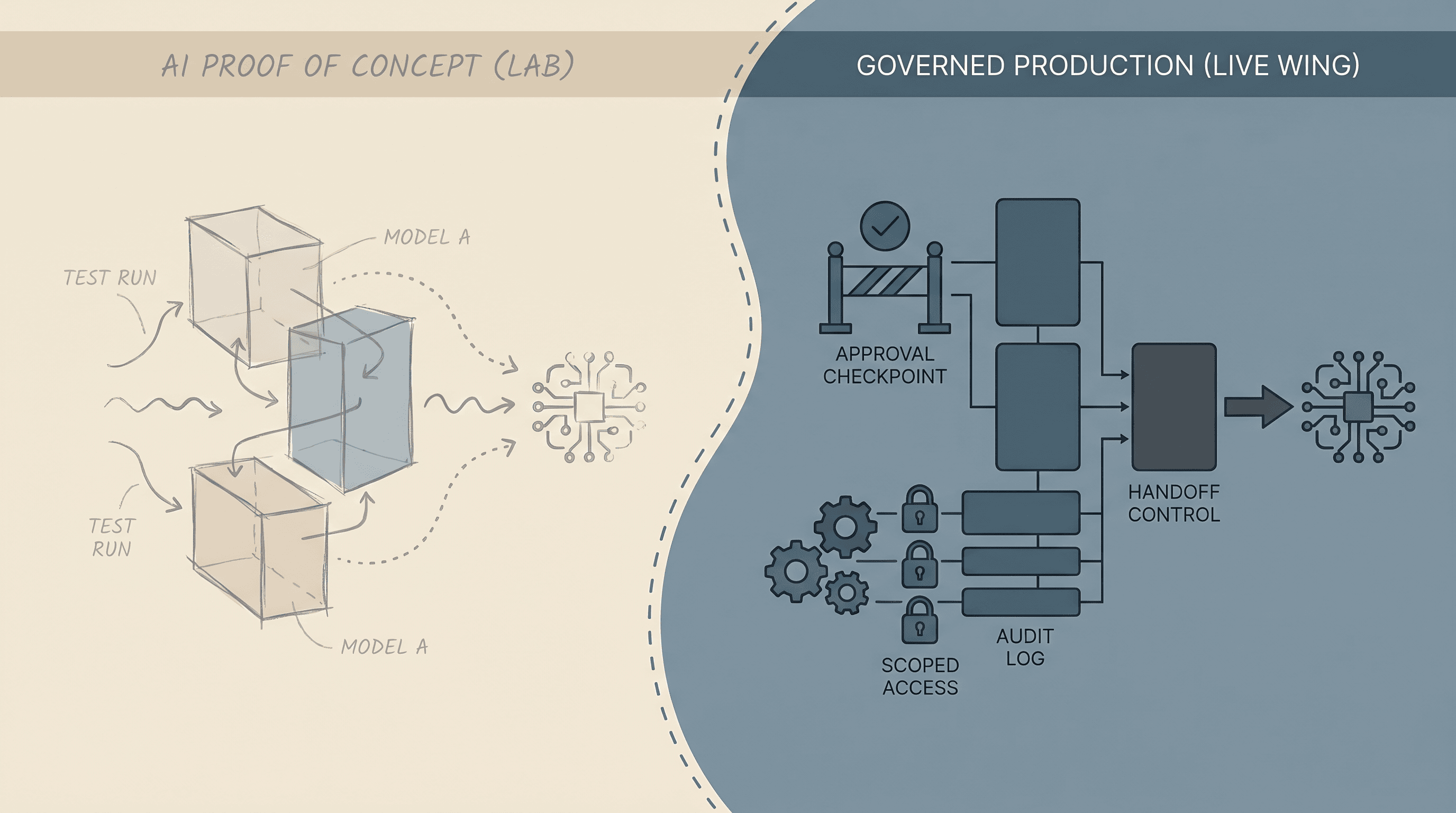
How the options differ
The cleanest distinction is which question each option is meant to answer.
Can the model handle the core task well enough on representative inputs?
Can the workflow run inside real systems with scoped access, approvals, ownership, and evidence the business can defend?
A bounded experiment, sample workflow, or prototype that proves feasibility on representative inputs.
A launchable workflow boundary with integrations, review rules, logging, controlled rollout, and a clear path to operate the system after launch.
Model behavior, sample-data fit, and whether the task deserves more investment at all.
Workflow ownership, messy data, systems integration, exception handling, and rollout risk.
Often narrow or stubbed while the team is still learning whether the workflow deserves production work.
The team defines the system of record, allowed app scope, touched records, and what happens when the data is incomplete or contradictory.
A light sanity check is usually enough while the team is still testing feasibility and narrowing the task.
Named reviewer authority, approval placement before risky actions, and clear rules for what can move automatically versus what must stop for review.
Enough notes to learn quickly and decide whether the opportunity is real.
Run history, touched-data evidence, approval records, and telemetry the team can inspect after each run.
Launch planning and rollback are not the goal yet. The job is to learn whether the workflow should advance.
A controlled launch path, a pause or rollback trigger, and clear operating rules when quality or trust drops in production.
You waste time hardening an idea that still might not matter.
You keep rerunning pilots while the real blocker is operations, ownership, governance, and launch discipline.
The team has not yet proven the task on real inputs.
You are still unsure whether AI is the right approach at all.
The workflow is not scoped tightly enough to define success.
You do not yet know the first usable output or the system of record.
The main uncertainty is still model behavior, not integration or rollout.
The core task already works and the real blocker is now integration, ownership, or launch risk.
Stakeholders are asking what the workflow can touch, who can publish changes, who approves critical steps, and what survives in the logs.
The team has a demo, but no clean path to connect it to CRM, ticketing, finance, or other live systems.
Another experiment would mostly delay the work around permissions, review rules, exception handling, and rollout.
Security, legal, or operations now need approval placement, scoped access, and evidence after each run.
You can name the owner, the system of record, and the conditions that should pause or roll back the workflow.
Where teams get this wrong
Most lost time comes from mismatching the engagement to the stage, not from picking the wrong tool.
Letting a proof of concept absorb production complexity before the workflow, owner, and success criteria are clear.
Treating model quality as the only real question after the team has already shifted to permissions, approvals, and launch controls.
Calling a workflow safe because somebody can click approve, even though approver authority, source context, and stop rules are still undefined.
Skipping the evidence layer, so nobody can prove what data the workflow touched or what happened after each run.
Running one more pilot when the real missing work is integration, ownership, logging, and rollout discipline.
Supporting reads and next steps
Use the linked service overview and supporting editorial to decide whether you still need validation or you are ready to ship.
FAQs
Short answers for the questions that usually come up once the problem is real.
Start with the audit before the next expensive wrong turn
The audit is built for exactly this stage: one workflow, one production problem, or one decision that needs to get clearer before more time is burned.
Related pages
Follow the next most relevant path based on the same decision, workflow, or rescue pattern.